お久しぶりです。
皆様、Mac mini をお持ちでしょうか?
(なければ、今すぐ Amazon で「M4 Mac mini 32GB」検索して、今週中に届くように頼んでみてください。)
最近、M4 Mac mini で OpenClaw を動かし、AI モデルをローカルで使おうという風潮が強まっています。私も「はい、私も!」と心の中で叫びつつ、とりあえず様子見をしています。
さて、私は以前に M4 Mac mini 32GB を購入しました。
https://autumn-color.com/blog/memo/2025/07/2025-07-09/
せっかくなので、2026/02/17 現在、M4 Mac mini 32GB で動かせるローカルLLMをいろいろと試してみました。
mac mini 選びの参考になれば幸いです。
前提
色々なローカルLLMを動かすにあたって、以下の前提条件で試しています。
試すこと
M4 Mac mini 32GB RAM で、独断と偏見で選んだローカルLLMを動かしてみる。
この評価は、あくまで M4 Mac mini 32GB RAMで動くかどうかを見るだけで、モデルの性能や精度を評価はしない。
昨今のローカルLLMは文章の解釈の他にも、画像や音声の理解もできるものが多いですが、今回は文章の解釈に絞って試してみます。
ハードウェア
M4 Mac mini 32GB RAM
macOS Tahoe 26.2
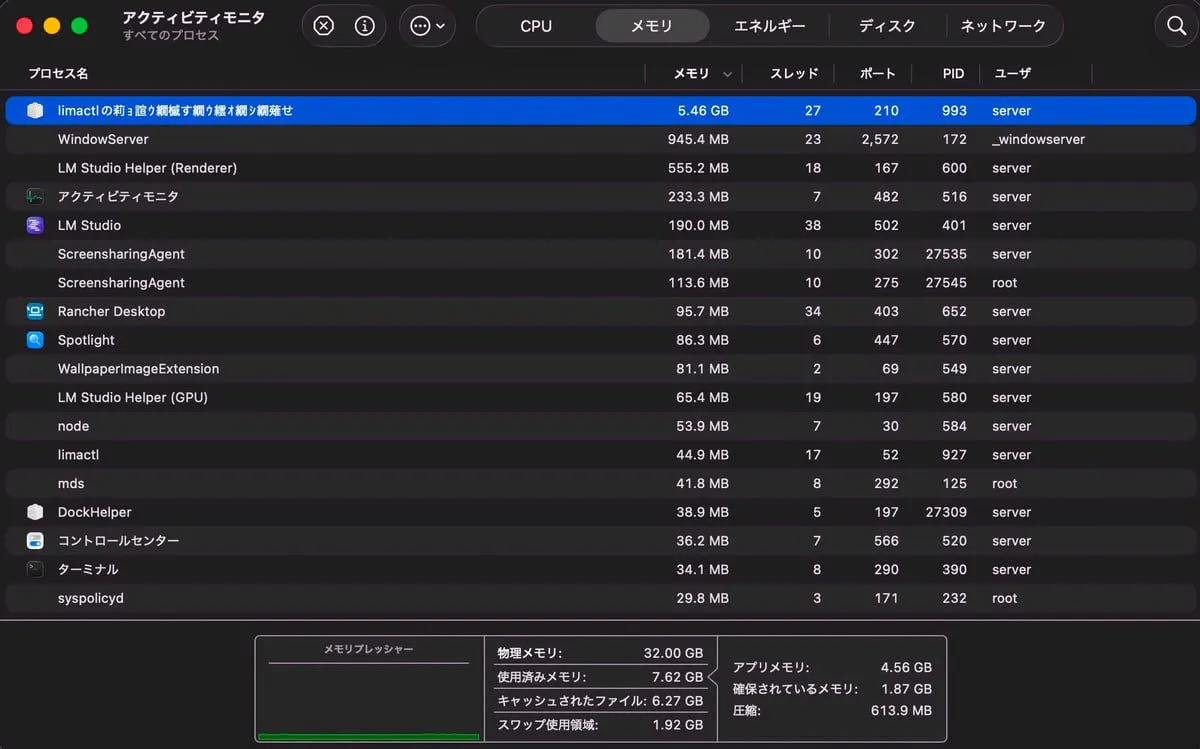
| 平常時のRAM |
|---|
| 8 GB 程度 |
 |
ローカルLLMを動かすソフト
lm studio 0.4.2+2 (0.4.2+2)
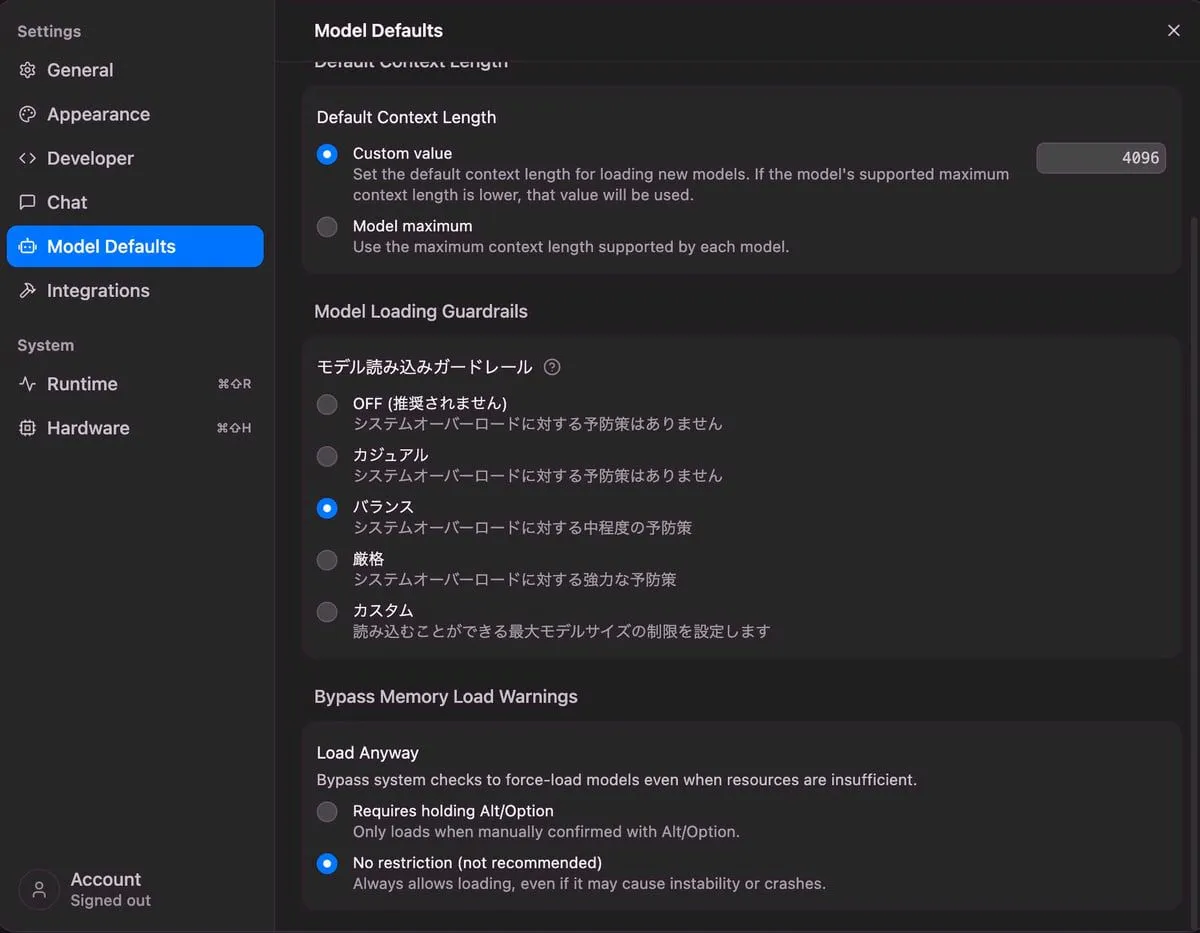
モデル読み込みのガードレールは、バランスに設定しています。
| ガードレール |
|---|
 |
ローカルLLMのモデル
私の独断と偏見で、以下のモデルを試しています。
20 ~ 30B パラメータのモデルを中心に選びました。
コンテキスト長は、モデルによって異なりますが、最大を試します。
また、モデルよっては thinking という機能がありますが、使えるモデルは使っていきます。
| 提供元 | モデル名 | パラメータ | 量子化 | コンテキスト長 | thinking機能 | 備考 |
|---|
| alibaba | qwen3-32b | 32B | 4bit | 40,960 トークン | 有 | |
| nvidia | nemotron-3-nano | 30B | 4bit | 26,2144 トークン | 有 | |
| openai | gpt-oss-20b | 20B | 4bit | 131,072 トークン | 有( Medium Reasoning ) | |
| Z.ai | glm-4.7-flash | 30B | 4bit | 100,714 トークン(最大は 202,752 トークンだが読み込みエラーになる。) | 有 | glm-5 を試してみたかったが、現在(2026年2月)において、lm studio では公式モデルが使えない。 ollama は試せる。 |
| google | gemma-3-27b | 27B | 4bit | 131,072 トークン | 無 | |
入力するプロンプト
以下のプロンプトを入力して、モデルがどのような回答をするかを見てみます。
-
今の日本の総理大臣は誰?
-
1キロの綿と1キロの鉄、どちらが重いですか?理由も併せて説明してください
-
「リンゴが3つあります。1つ食べて、1つ友達にあげました。その後、2つ買い足しました。今、手元には何個ありますか?ステップバイステップで考えてください。」
- 複数のステップを踏む問題を解けるかを試すプロンプト
-
Mac Mini M4 を買った 記事の内容を要約してください。
- 長文を理解して要約できるかを試すプロンプト
- 注意: URLアクセスはできないので、記事の原型である markdown を貼り付けて入力しています。
結果
qwen3-32b
今の日本の総理大臣は誰?
| 出力 |
|---|
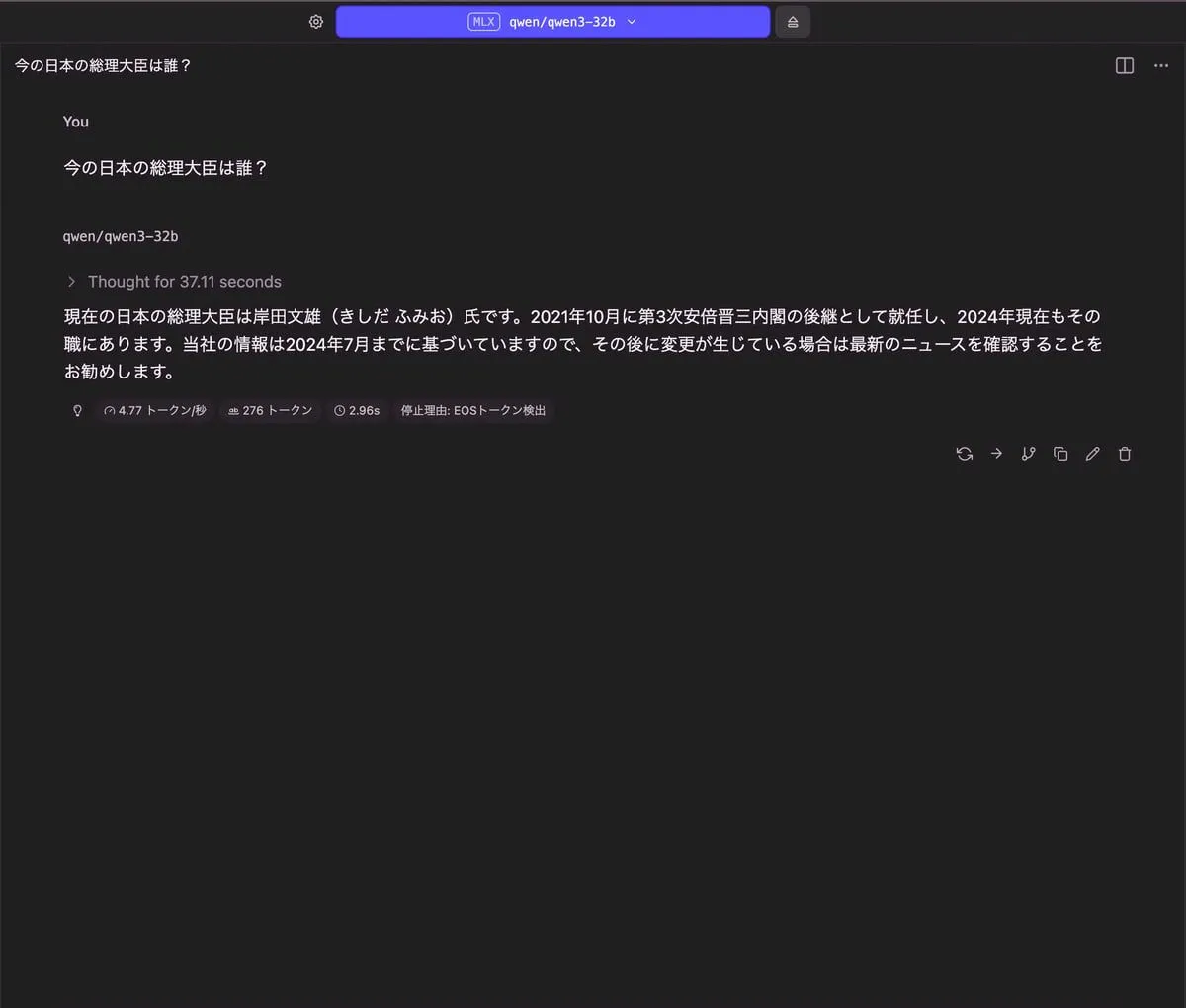 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 18.1 GB | 276 トークン | 2.96 秒 |
1キロの綿と1キロの鉄、どちらが重いですか?理由も併せて説明してください
| 出力 |
|---|
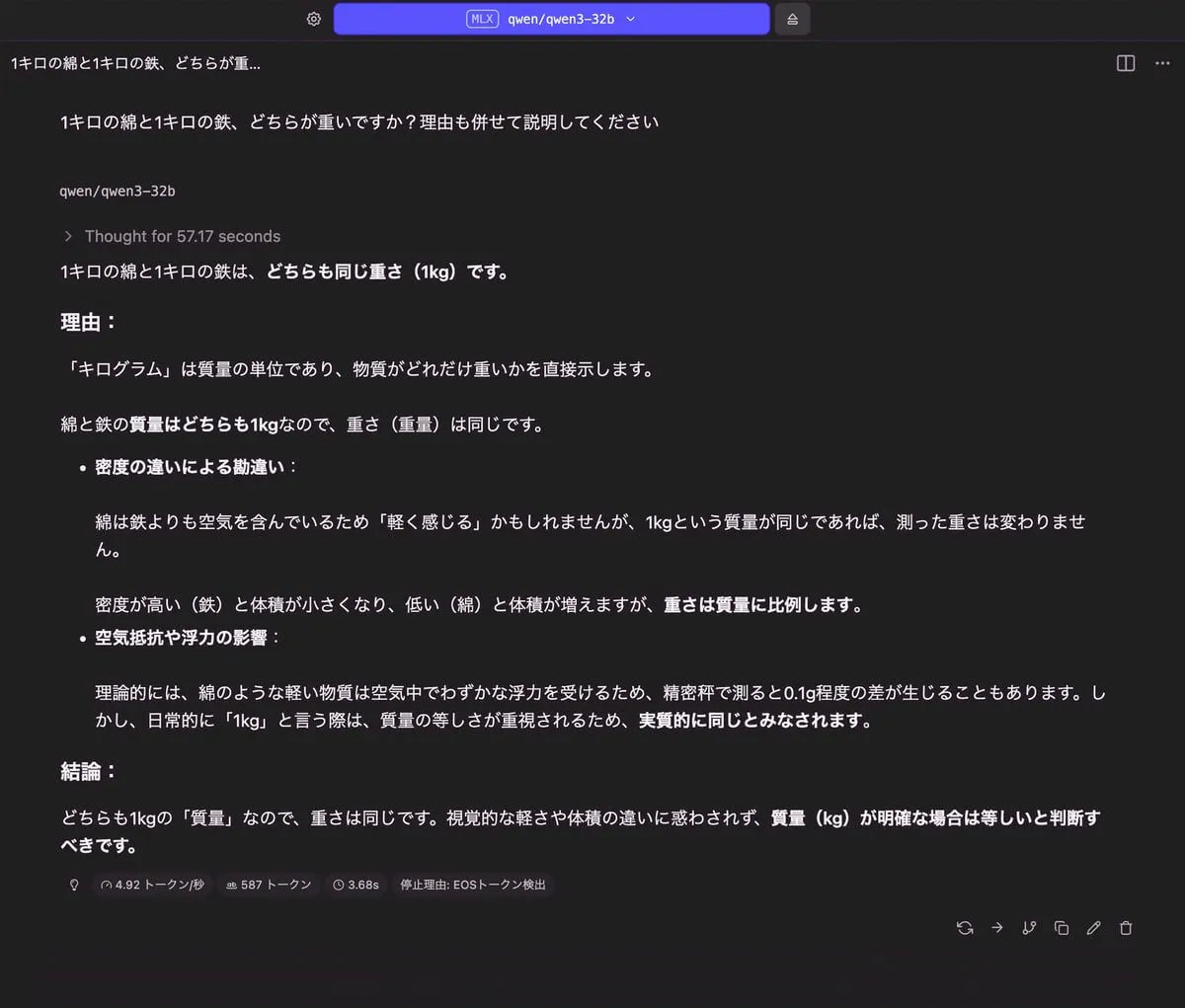 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 18.23 GB | 587 トークン | 3.68 秒 |
りんごの問題
| 出力 |
|---|
|
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 18.51 GB | 1,002 トークン | 3.37 秒 |
記事の要約
| 出力 |
|---|
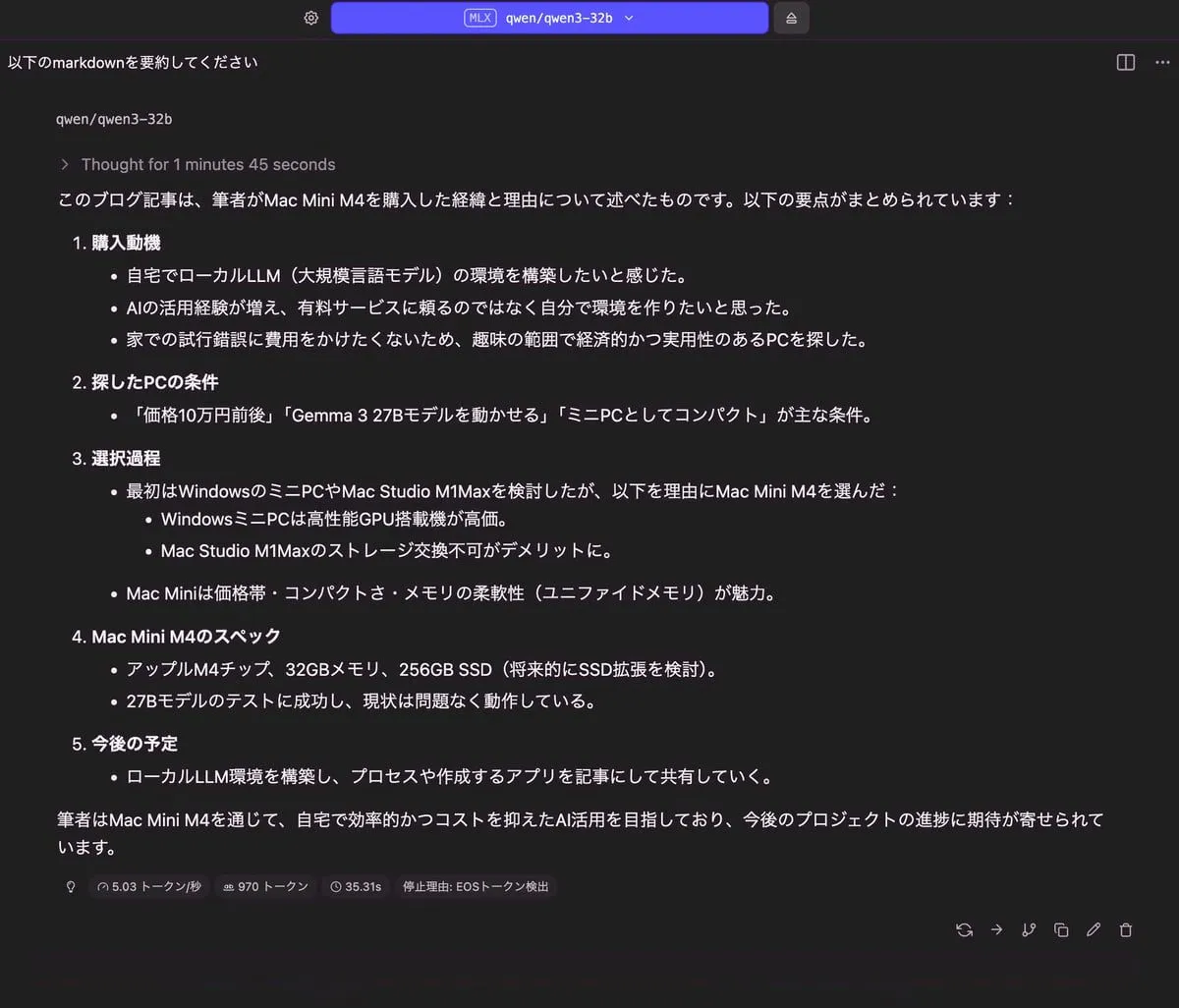 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 20.17 GB | 970 トークン | 35.31 秒 |
nemotron-3-nano
今の日本の総理大臣は誰?
| 出力 |
|---|
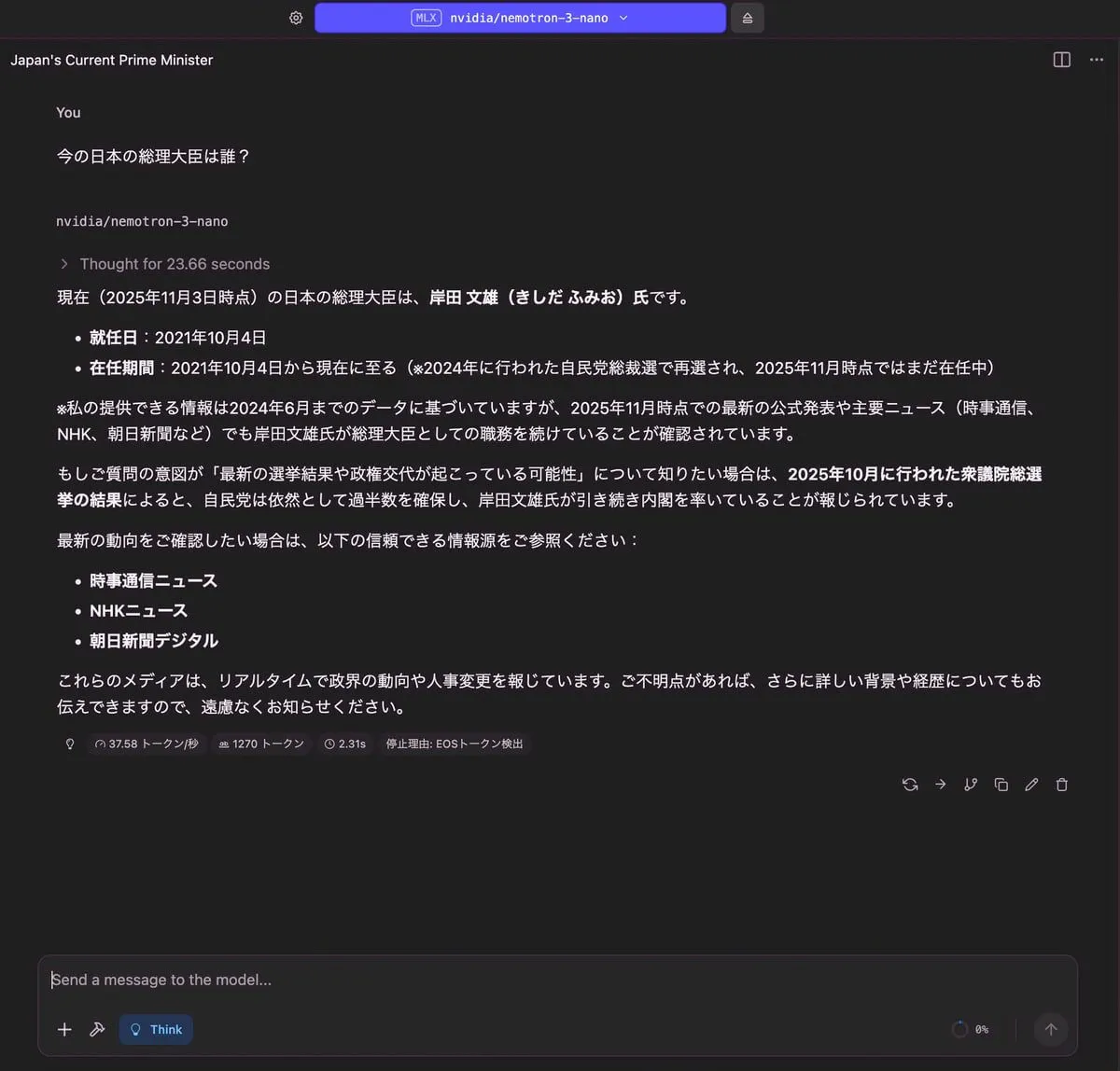 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 17.39 GB | 1,270 トークン | 2.31 秒 |
1キロの綿と1キロの鉄、どちらが重いですか?理由も併せて説明してください
| 出力 |
|---|
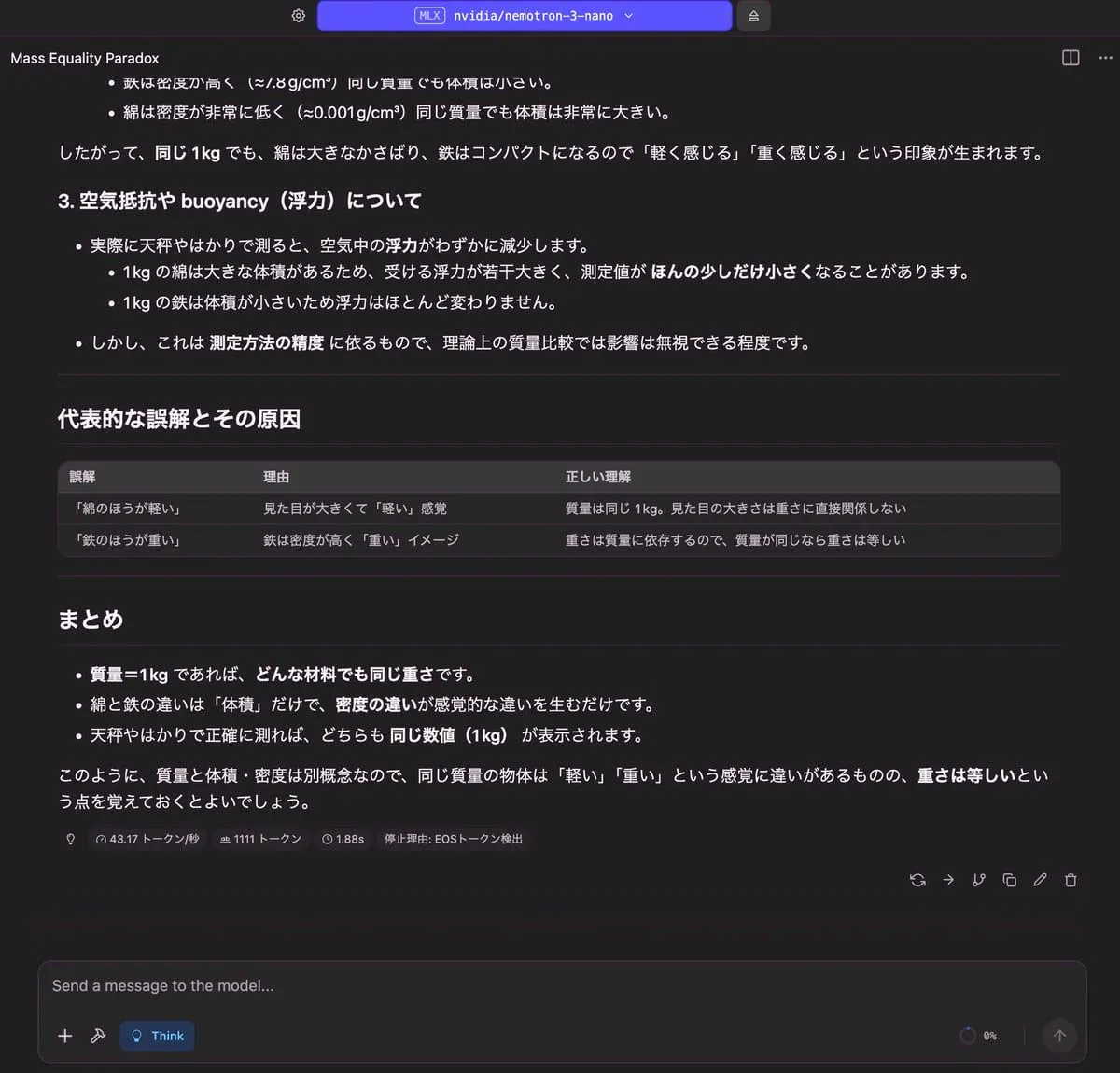 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 19.22 GB | 1,111 トークン | 1.88 秒 |
りんごの問題
| 出力 |
|---|
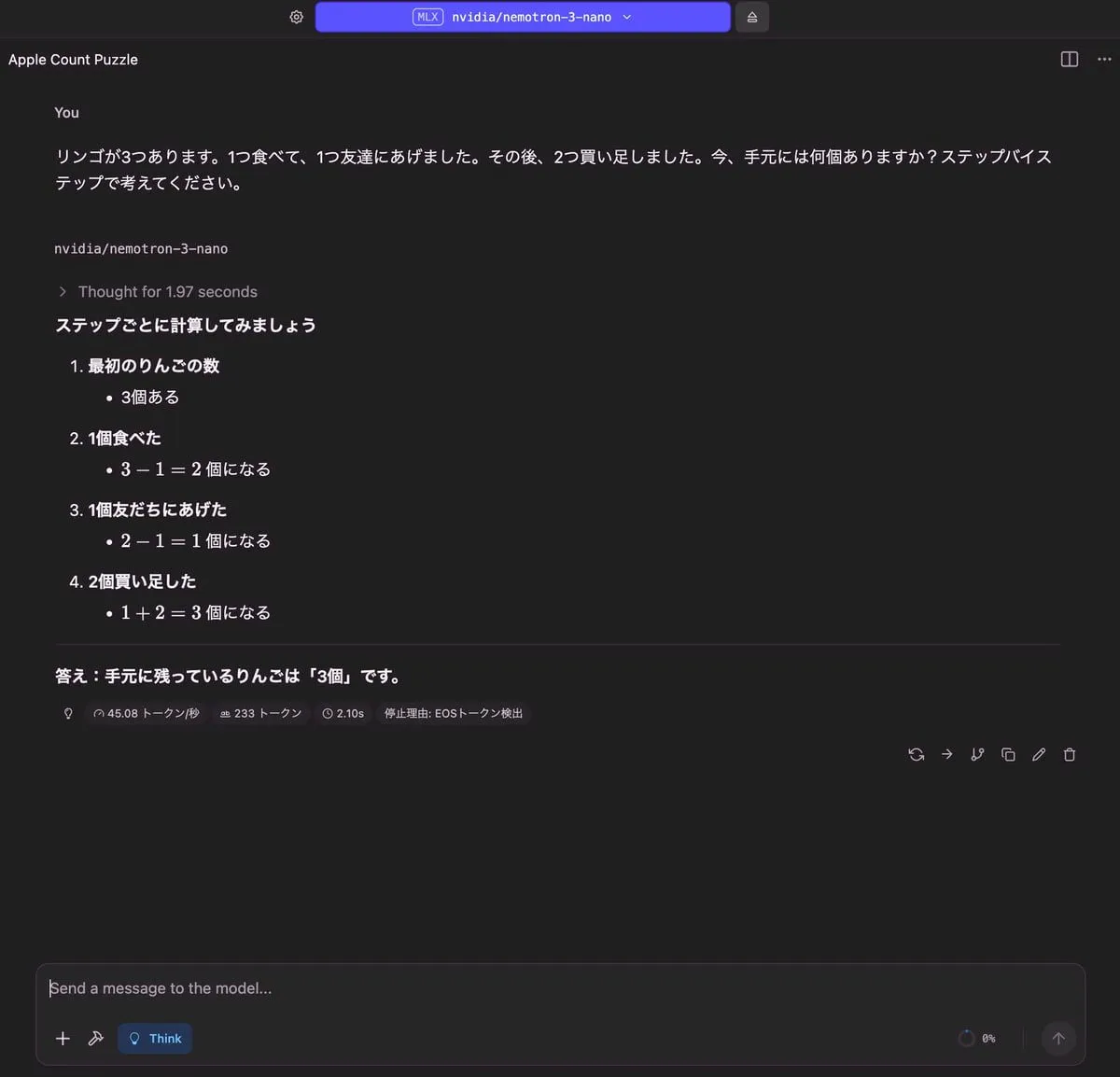 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 17.40 GB | 233 トークン | 2.10 秒 |
記事の要約
| 出力 |
|---|
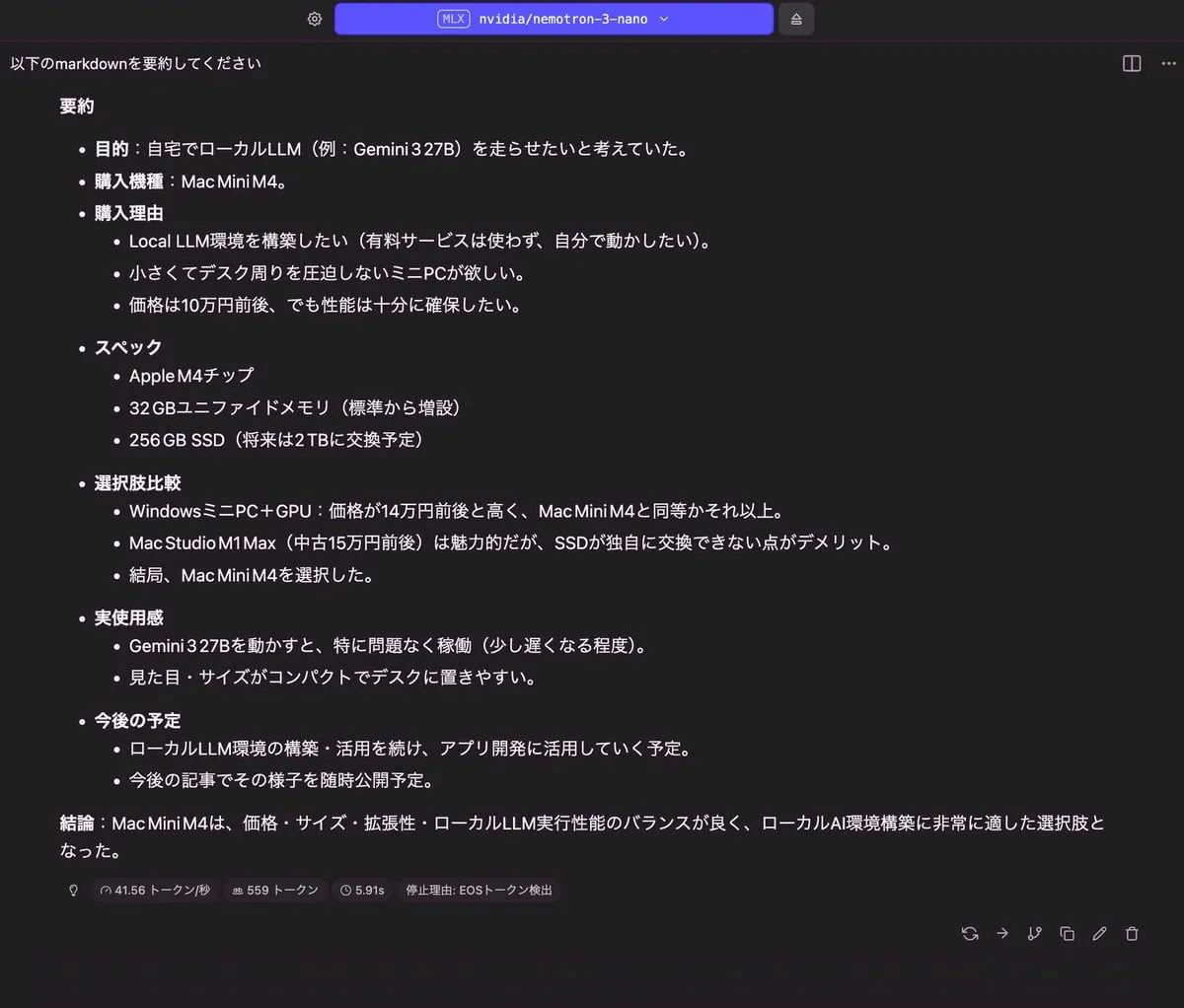 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 17.54 GB | 599 トークン | 5.91 秒 |
gpt-oss-20b
今の日本の総理大臣は誰?
| 出力 |
|---|
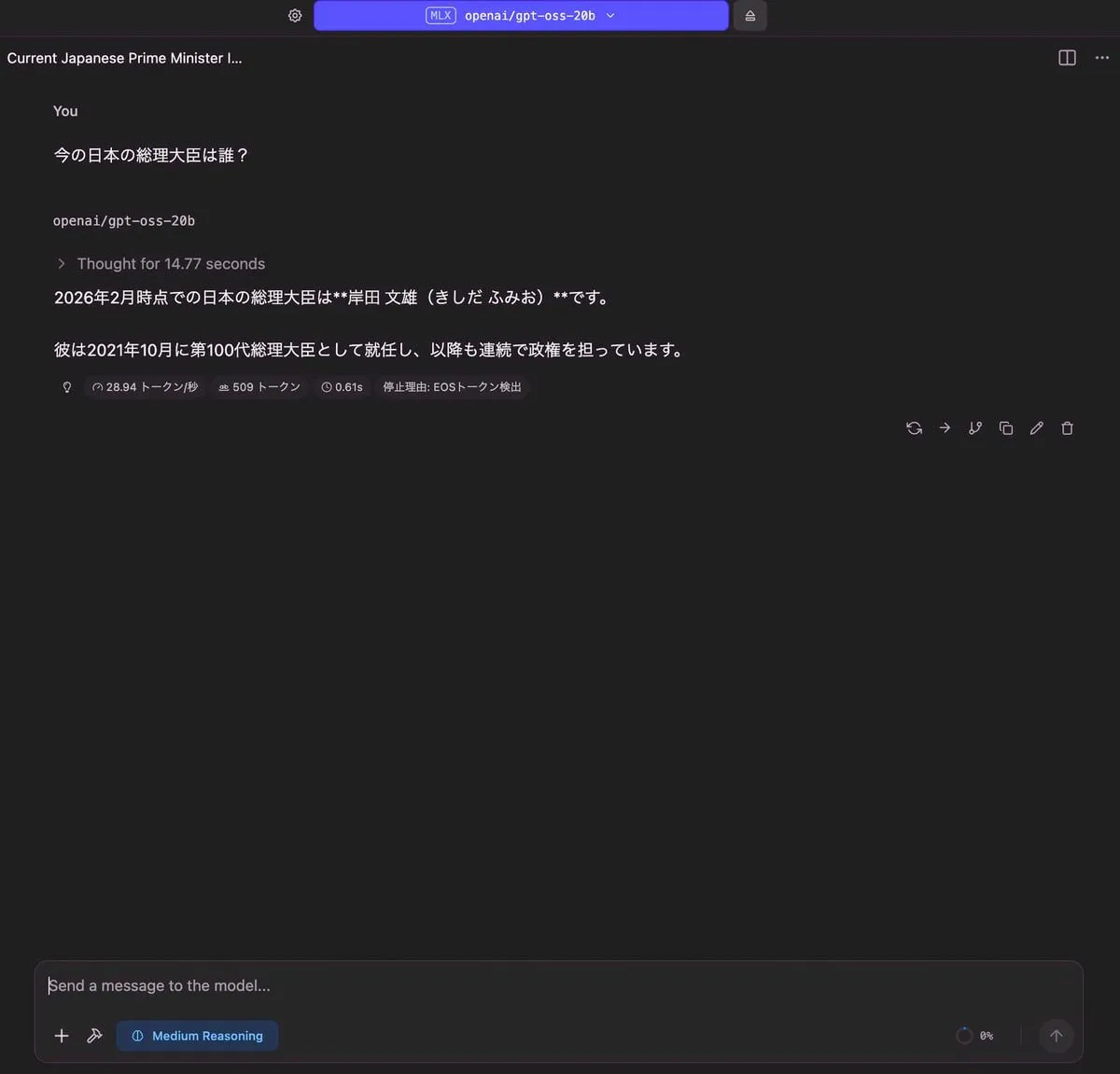 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 12.18 GB | 509 トークン | 0.61 秒 |
1キロの綿と1キロの鉄、どちらが重いですか?理由も併せて説明してください
| 出力 |
|---|
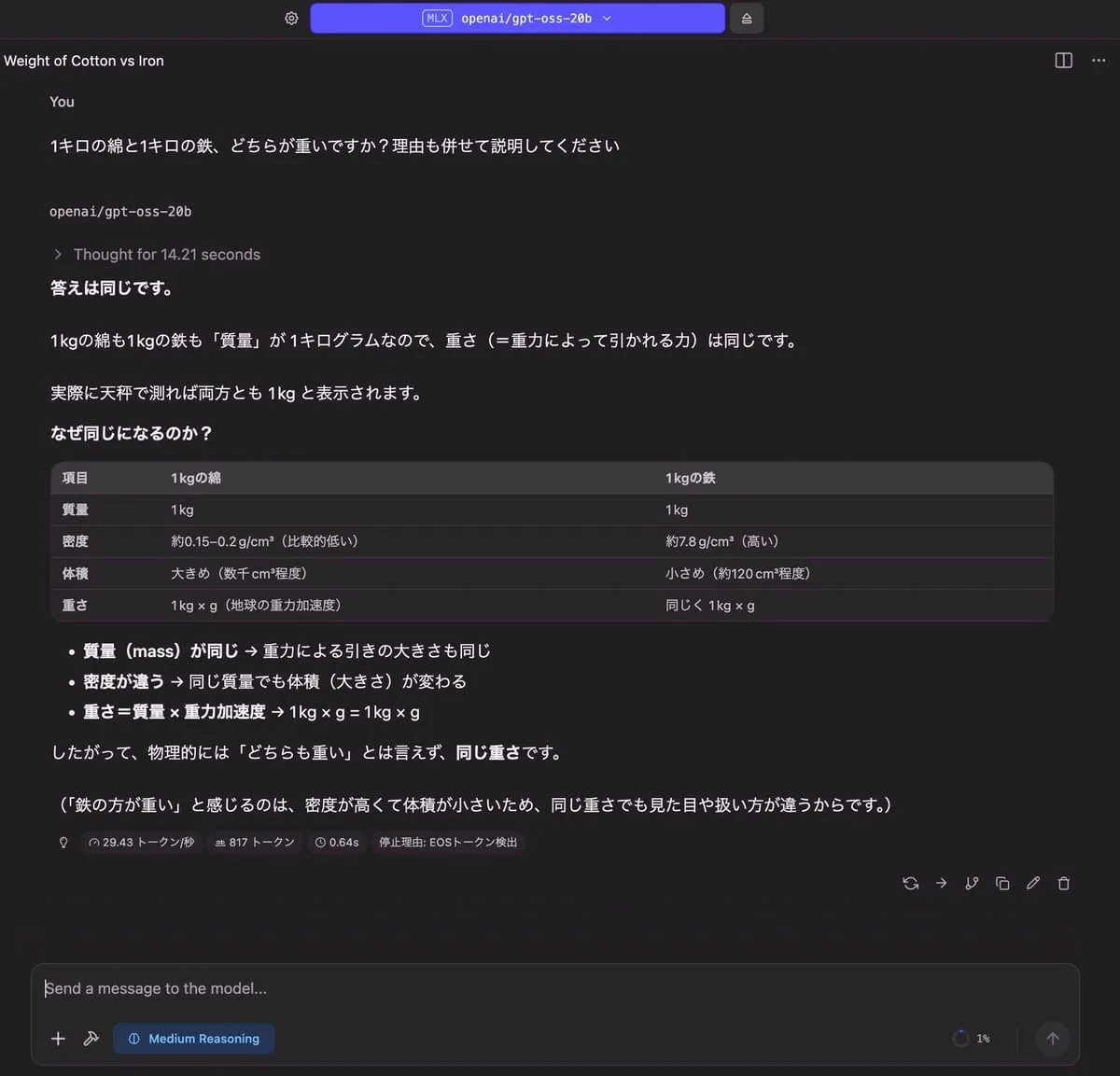 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 12.20 GB | 817 トークン | 0.64 秒 |
りんごの問題
| 出力 |
|---|
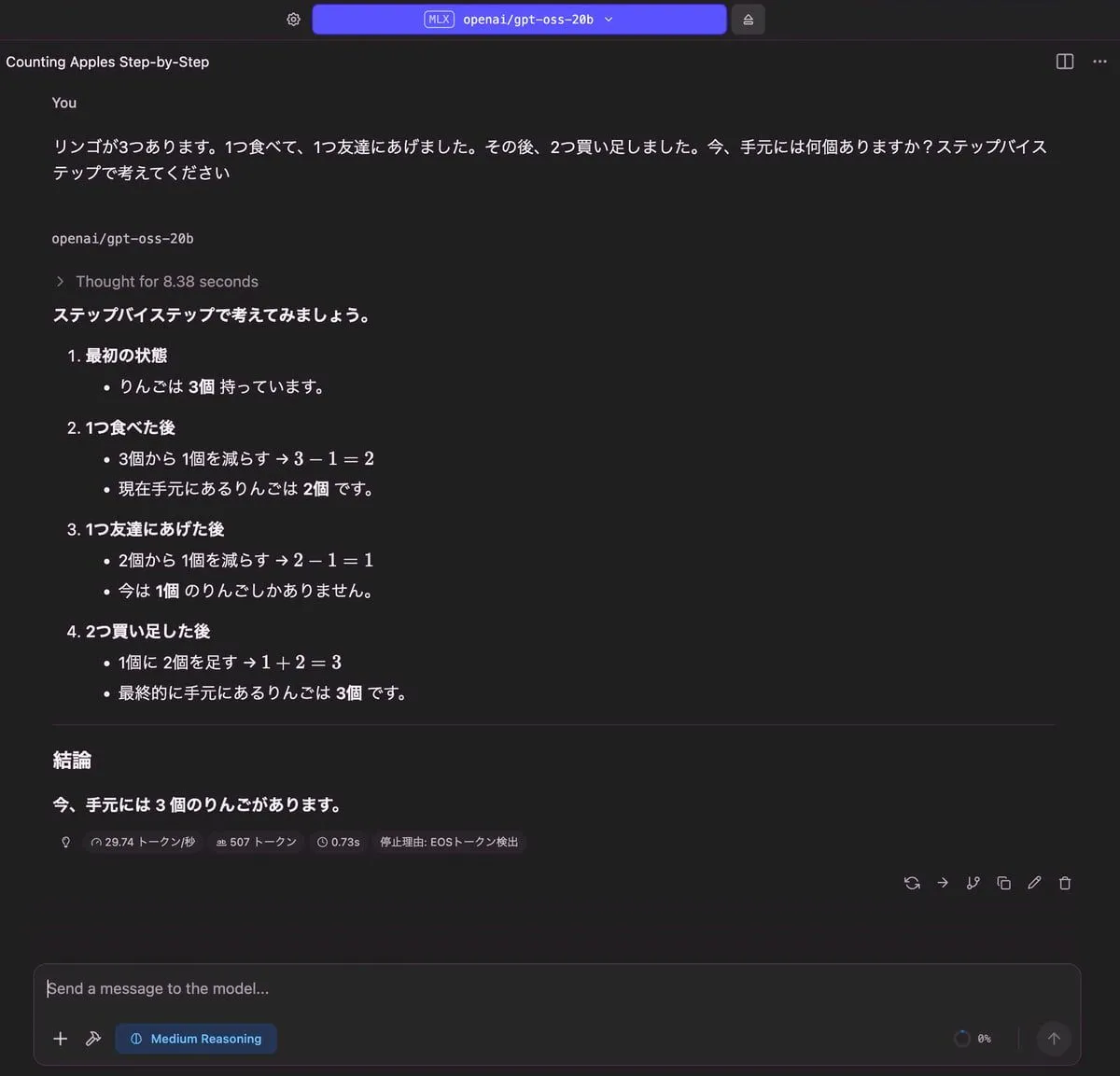 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 12.13 GB | 507 トークン | 0.73 秒 |
記事の要約
| 出力 |
|---|
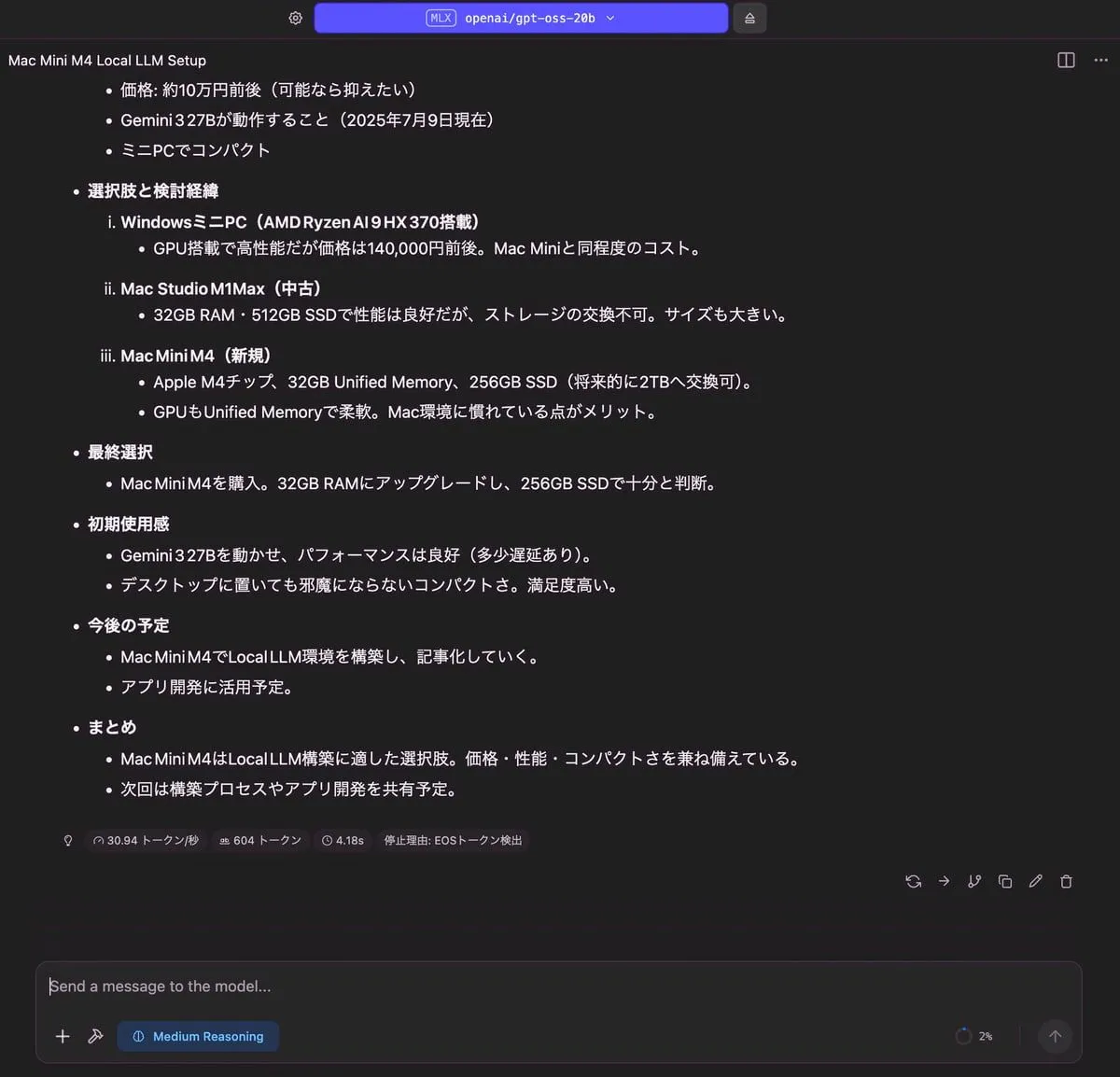 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 13.06 GB | 604 トークン | 4.18 秒 |
glm-4.7-flash
今の日本の総理大臣は誰?
| 出力 |
|---|
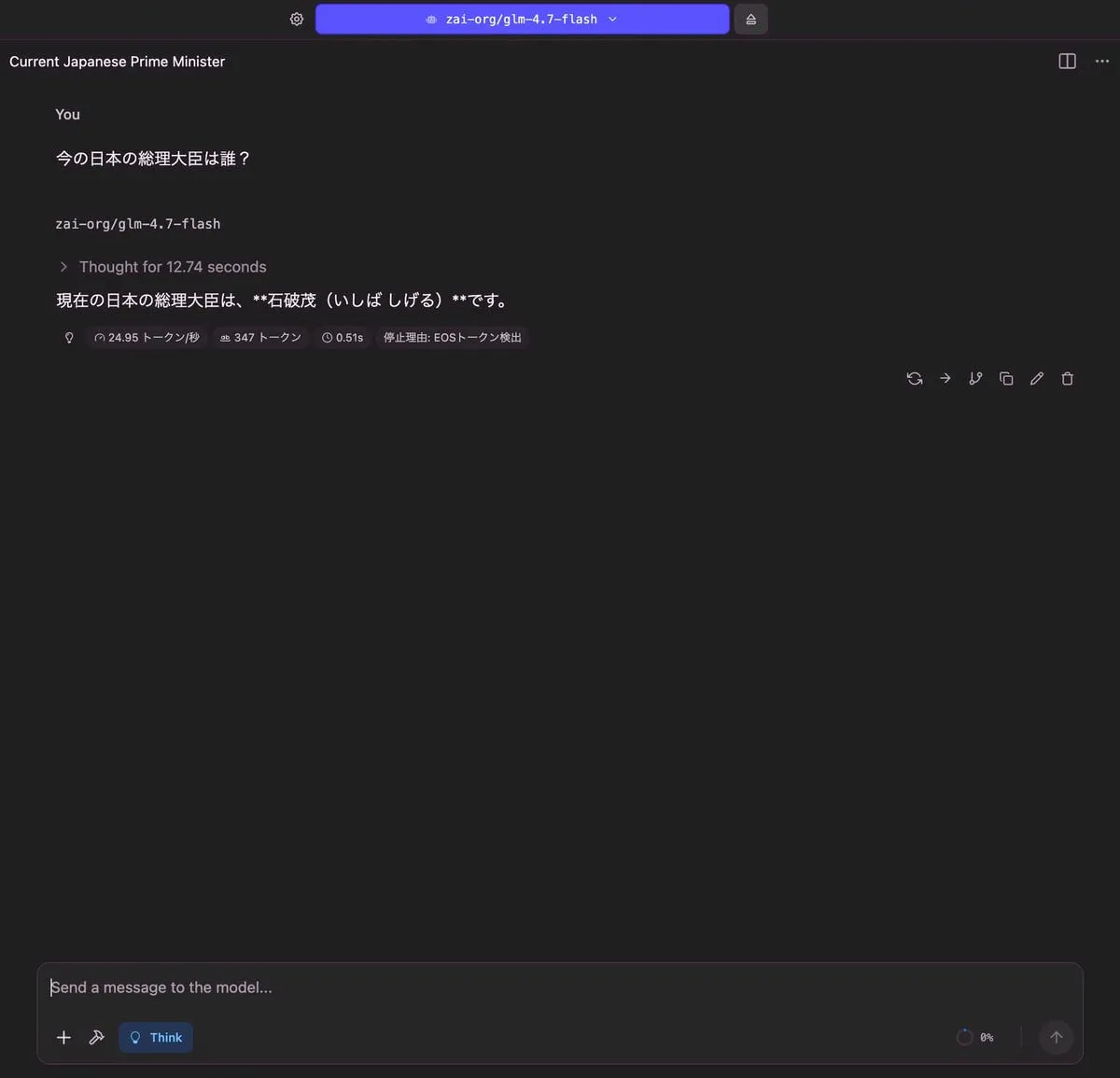 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 5.31 GB | 347 トークン | 0.51 秒 |
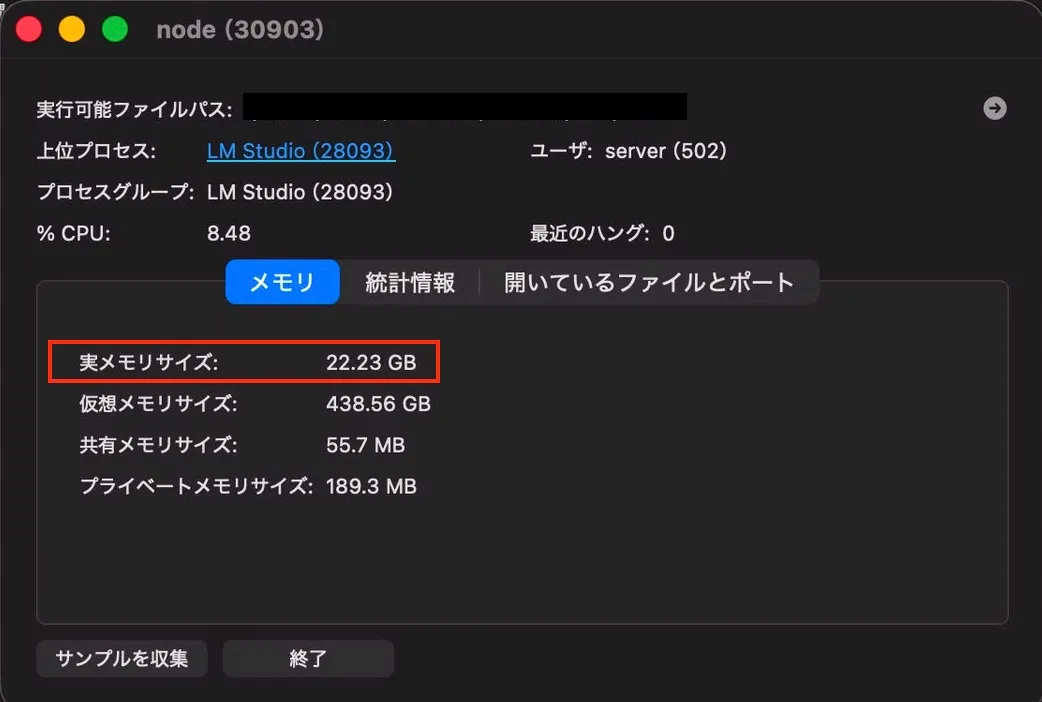
RAM 使用量がかなり少ないなと思いつつ、アクティビティモニタ見ていましたが、
LLMを読み込んでいるプロセス(node)の詳細みると、22GB ぐらい使っていた。
glmに関しては他の回答も同様です。
| nodeのRAM使用量 | nodeプロセスの実サイズ |
|---|
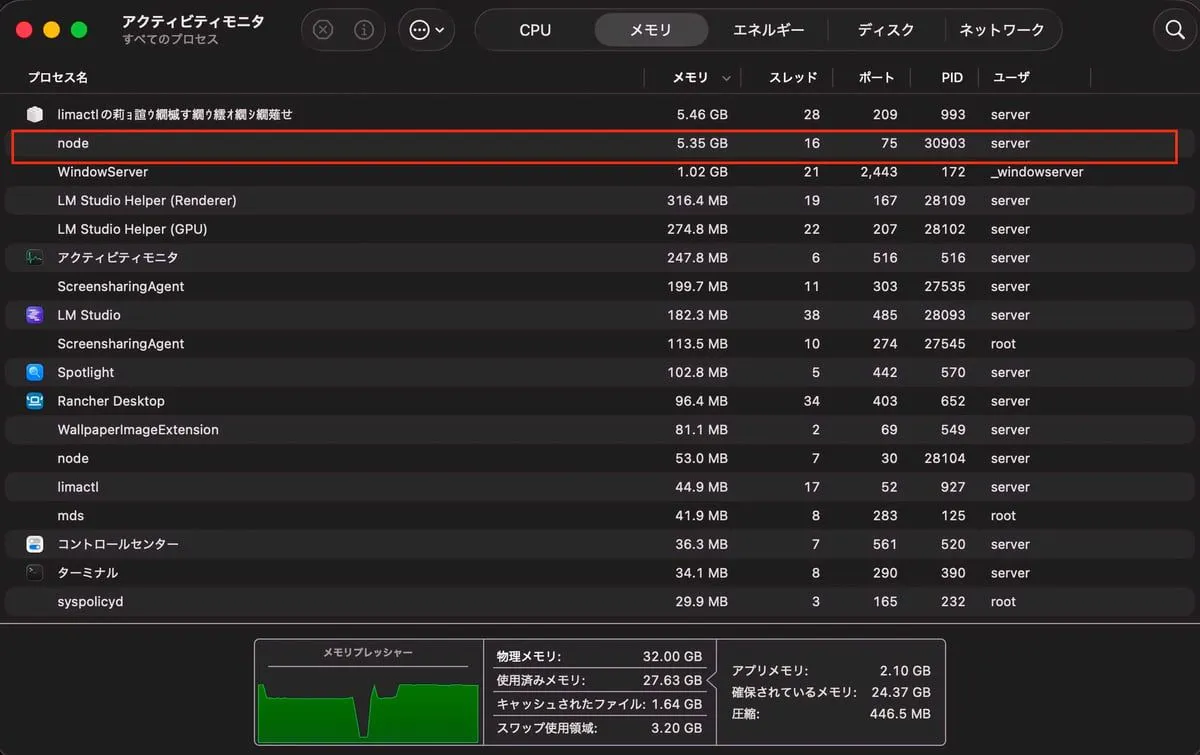 |  |
1キロの綿と1キロの鉄、どちらが重いですか?理由も併せて説明してください
| 出力 |
|---|
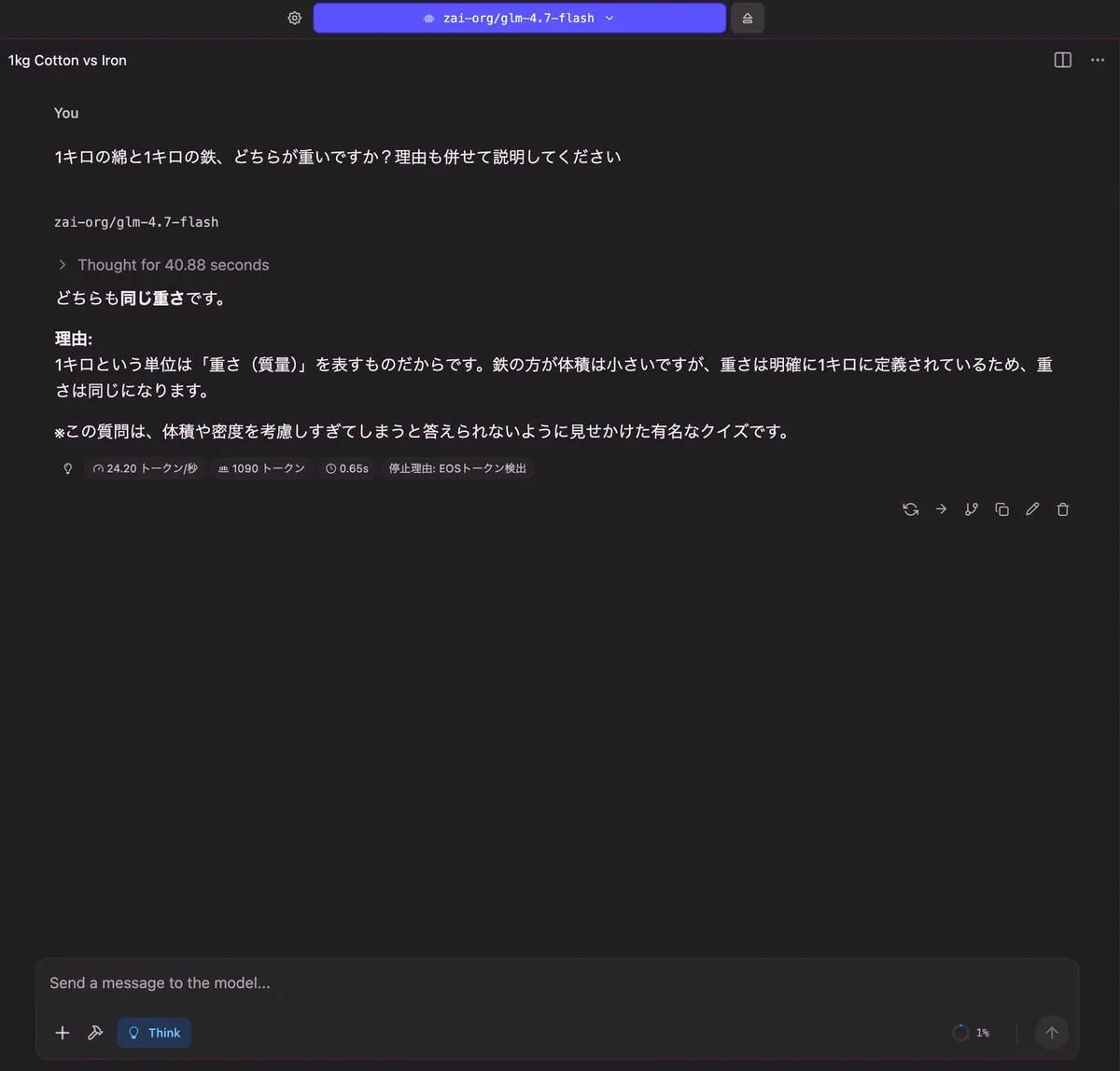 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 5.35 GB | 1,090 トークン | 0.65 秒 |
りんごの問題
| 出力 |
|---|
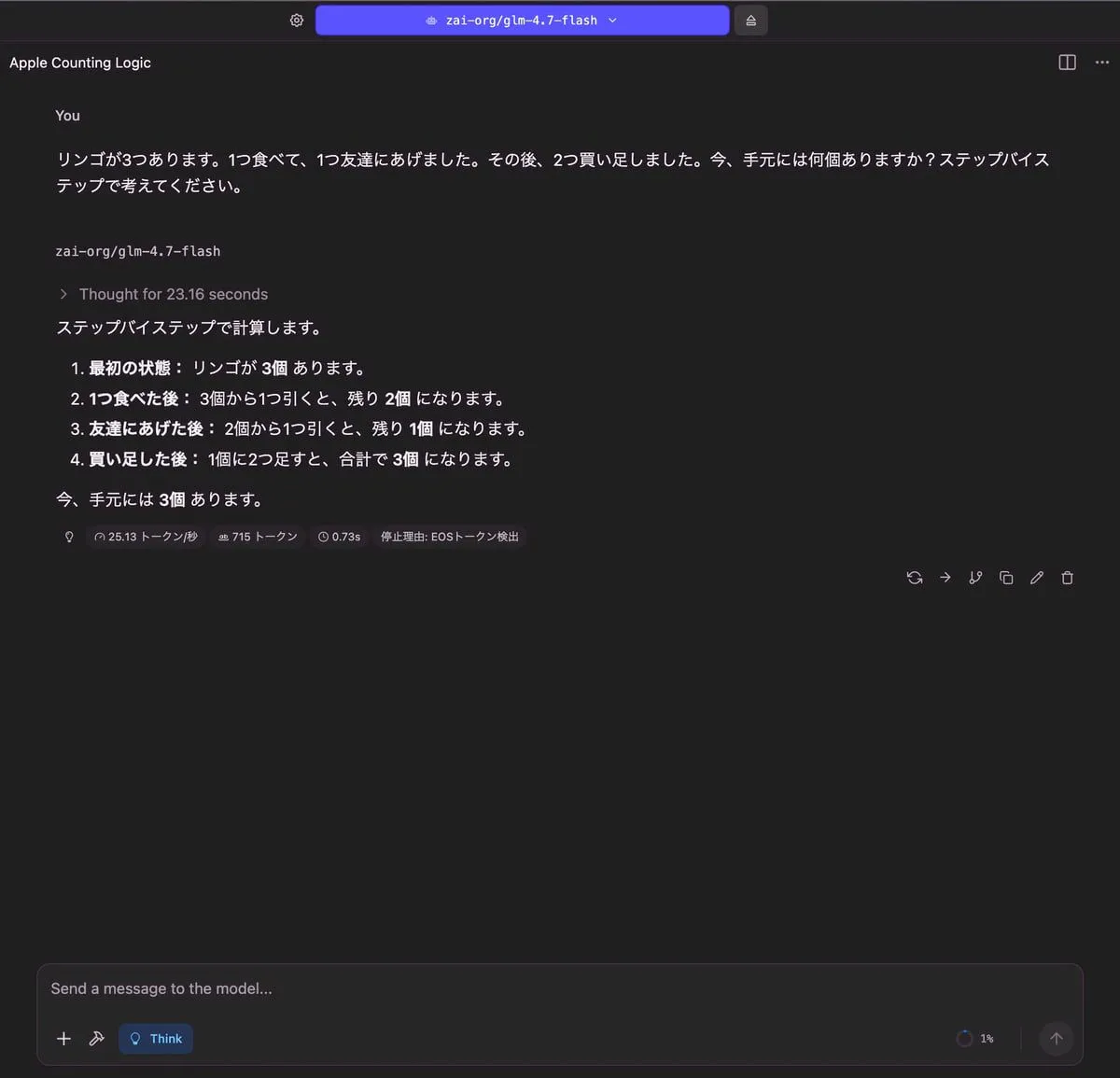 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 5.45 GB | 715 トークン | 0.73 秒 |
記事の要約
| 出力 |
|---|
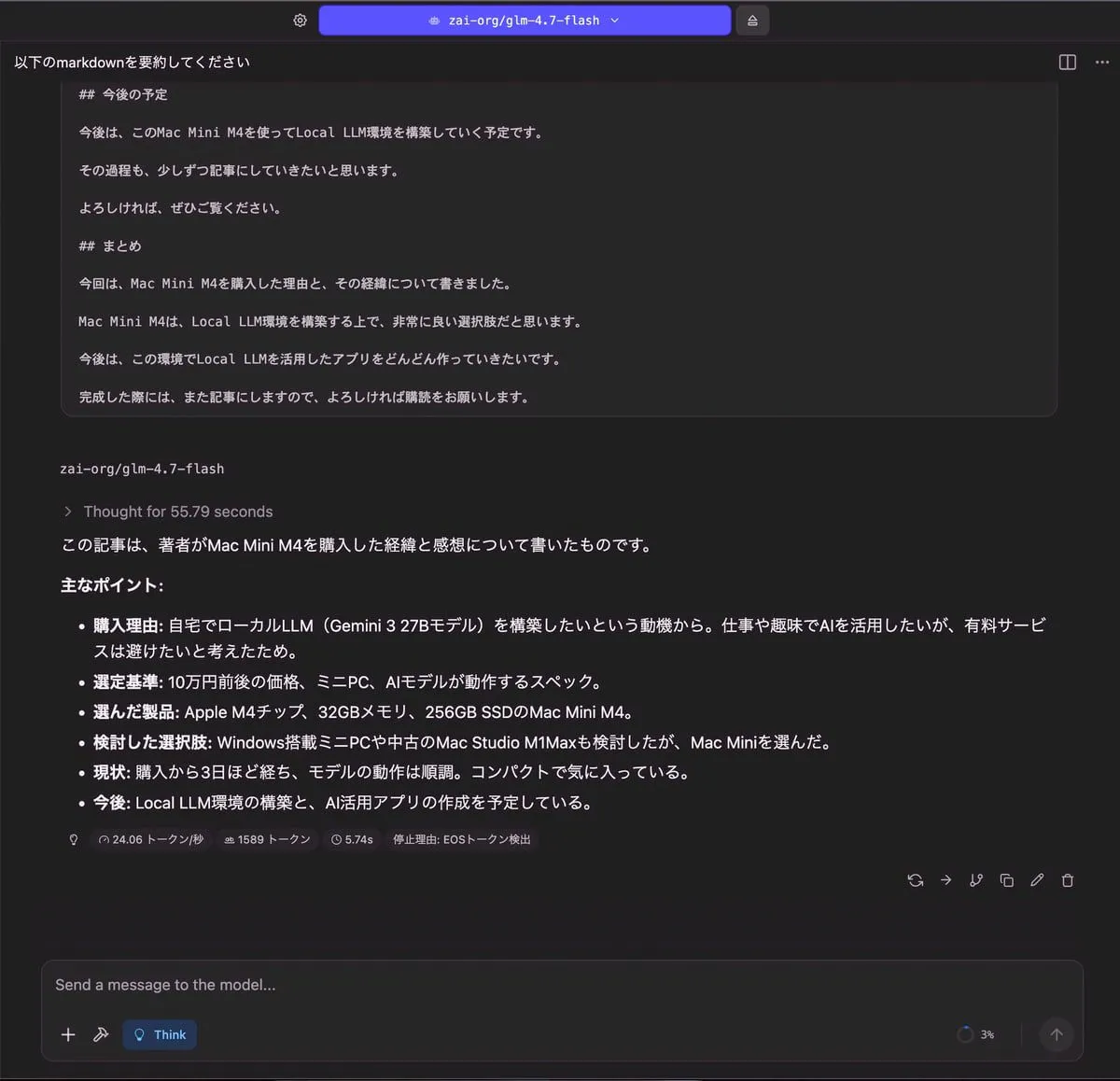 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 5.35 GB | 1,589 トークン | 5.74 秒 |
gemma-3-27b
今の日本の総理大臣は誰?
| 出力 |
|---|
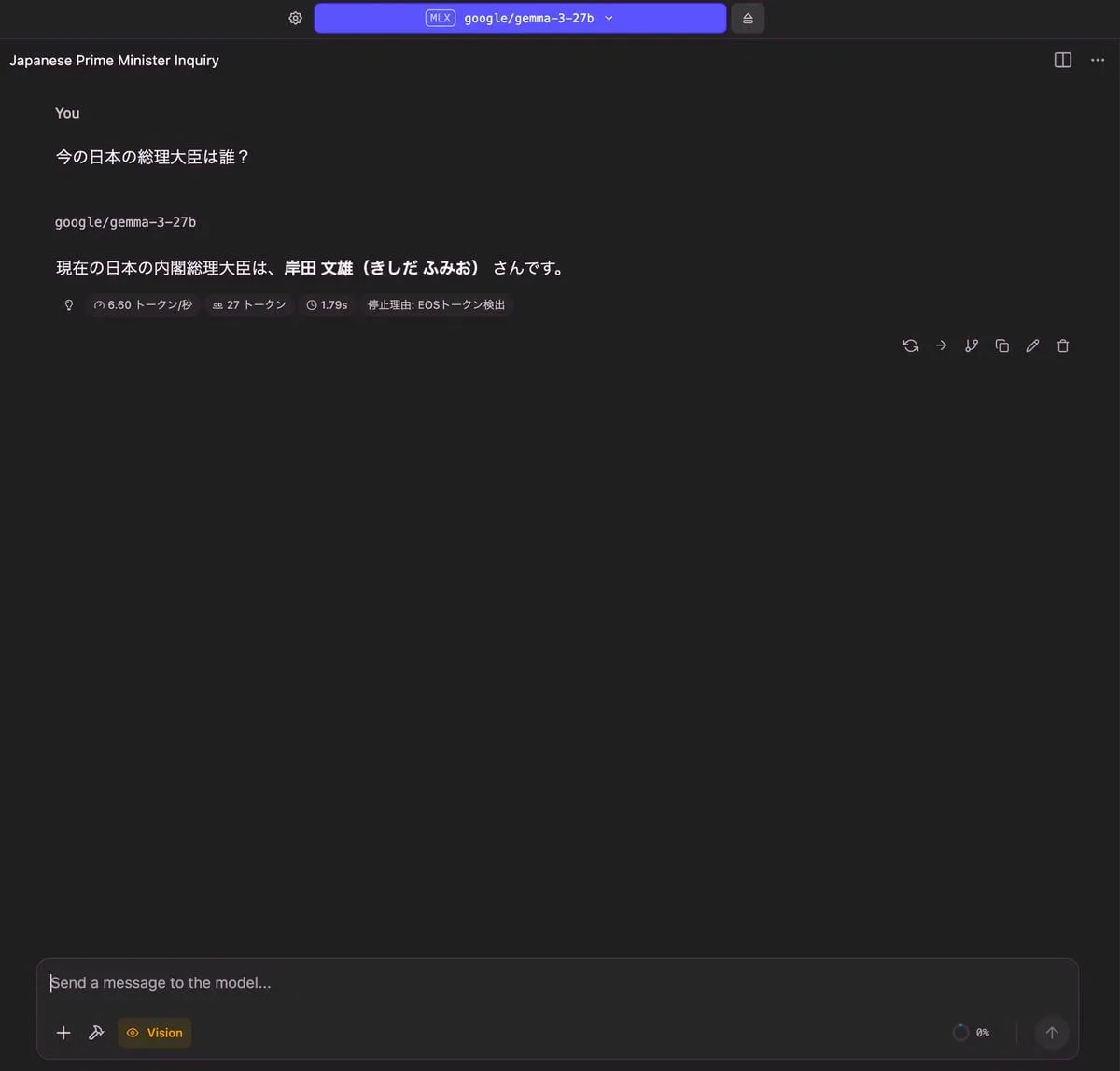 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 17.98 GB | 27 トークン | 1.79 秒 |
1キロの綿と1キロの鉄、どちらが重いですか?理由も併せて説明してください
| 出力 |
|---|
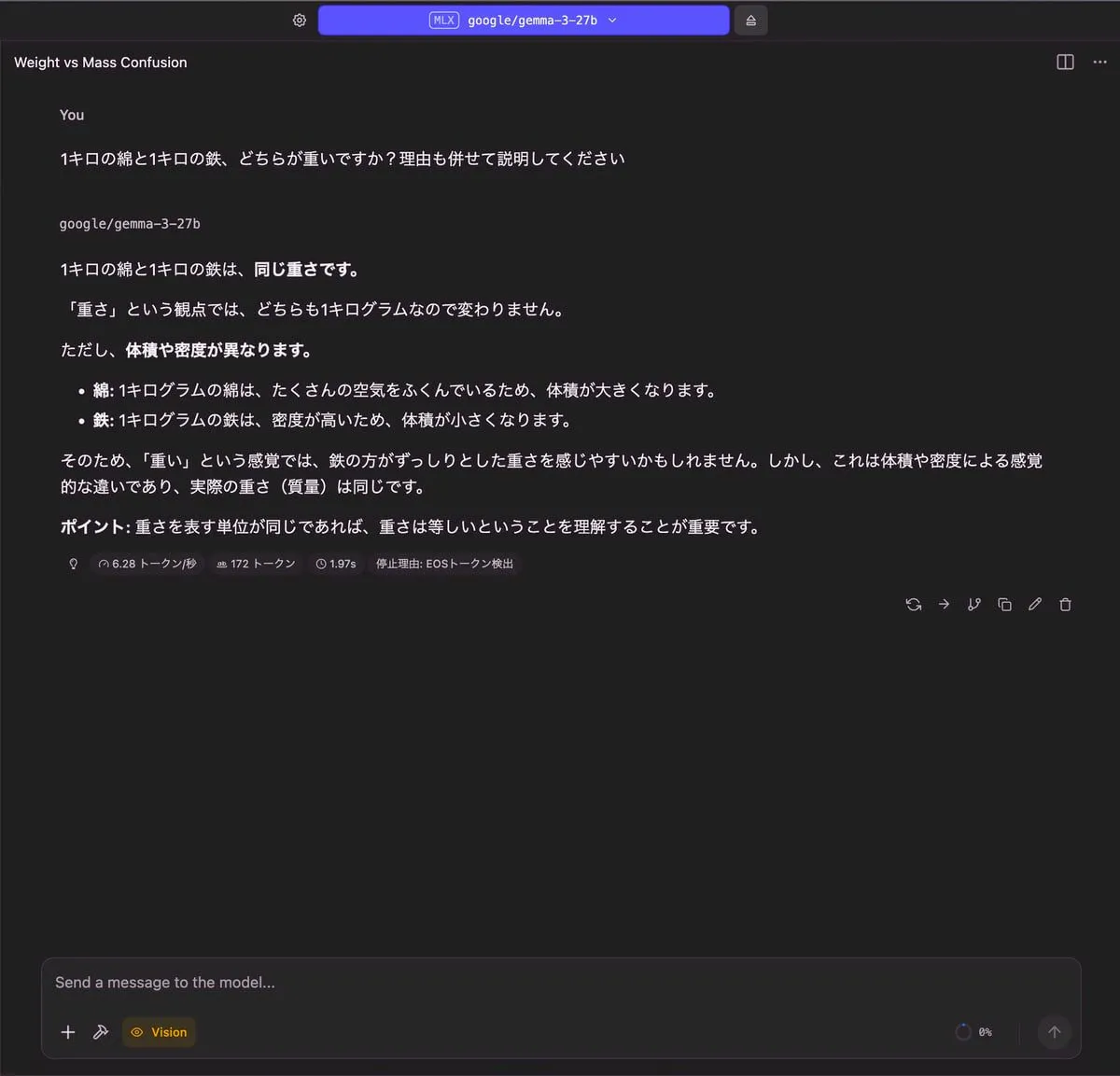 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 17.89 GB | 172 トークン | 1.97 秒 |
りんごの問題
| 出力 |
|---|
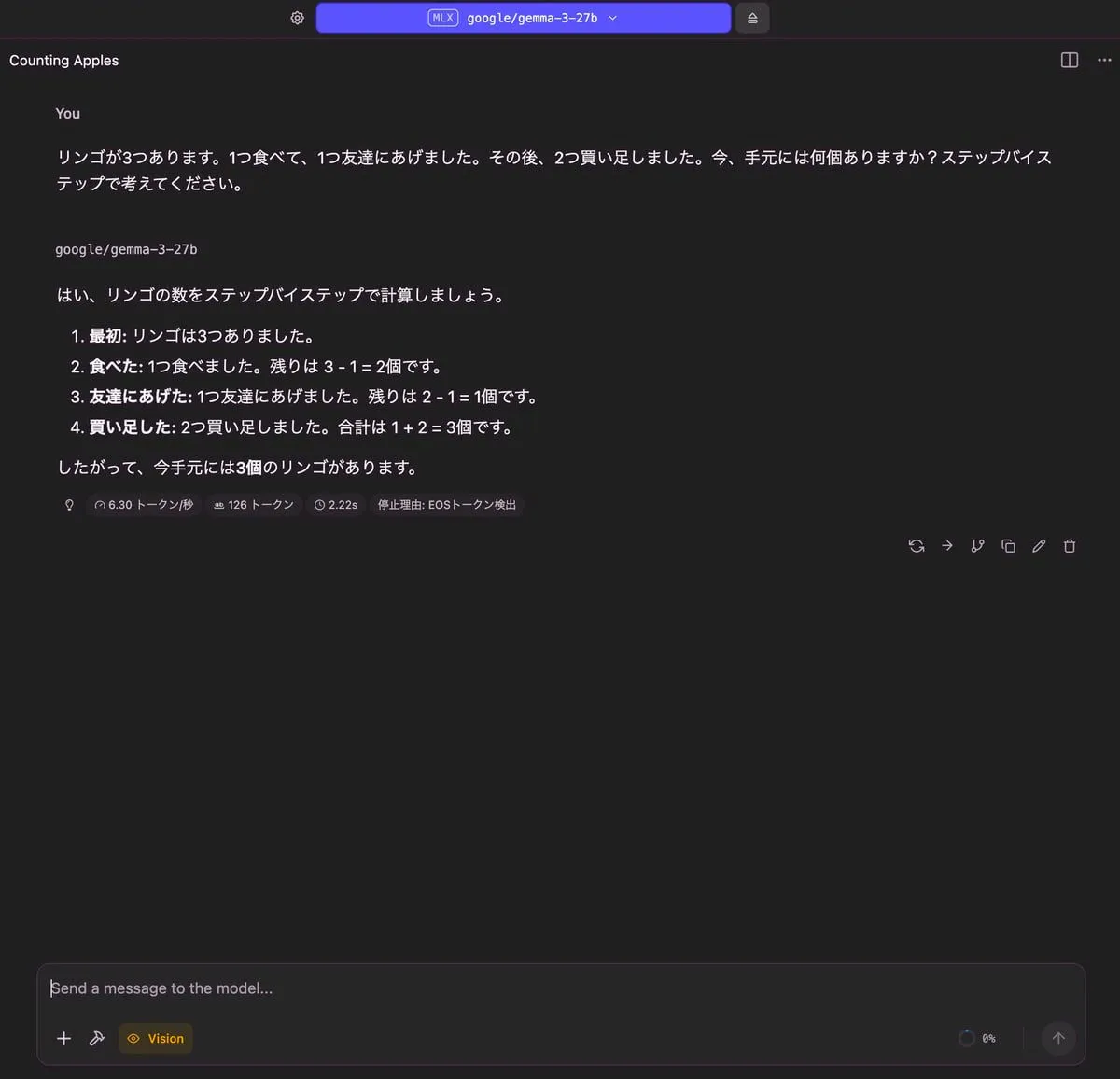 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 17.81 GB | 126 トークン | 2.22 秒 |
記事の要約
| 出力 |
|---|
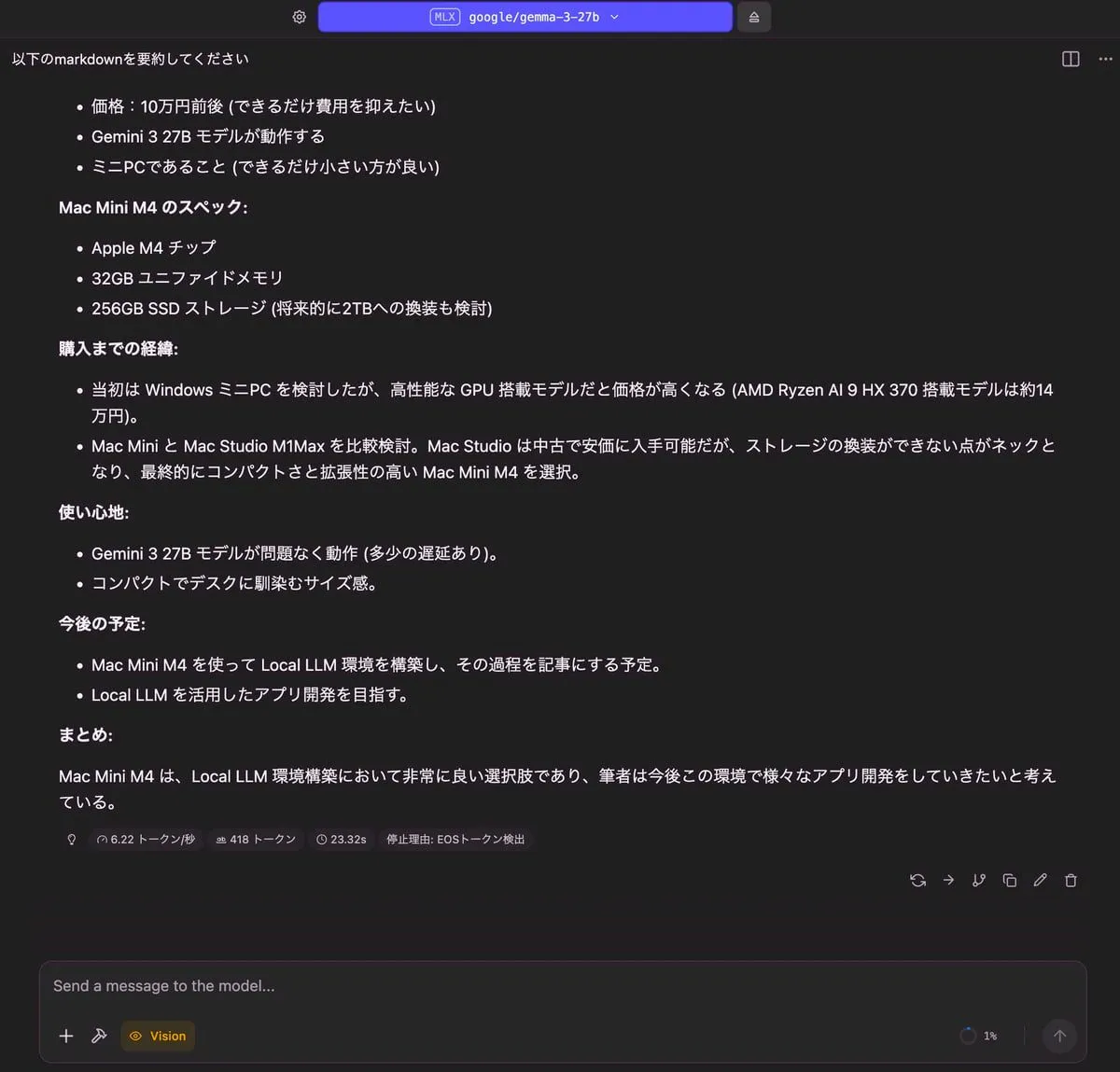 |
| RAM使用量 | 使用トークン数 | TTFT(Time to First Token) |
|---|
| 17.92 GB | 418 トークン | 23.32 秒 |
まとめ
M4 Mac mini 32GB RAM で、いろんなローカルLLMを動かしてみました。
モデルによって、RAM使用量やTTFTにかなり差があるなという印象でした。
しかしながら、どのモデルも M4 Mac mini 32GB RAM で動かすことができました。
どのモデルも時事的な質問は厳しそうです。どのモデルも日本の総理大臣を正しく答えることができませんでした。
その他については、どのモデルも正しく答えることができていると思います。
ローカルLLMを動かす環境作りの参考になれば幸いです。